Intermittent Demand and Multiple Temporal Aggregation
In the ADIDA tutorial we aggregated time series using different sized "time buckets". This allowed us to remove, or heavily reduce, intermittency within the data. We then made a prediction using this aggregated series and saw that different sized buckets gave different forecasts, with some better than others. The selection for each series was optimised by choosing an aggregation size that reduced the error (RMSSE) between a forecast and a validation set.
Instead of choosing just a single aggregation size, this tutorial will investigate combining multiple sizes in an effort to produce a more robust forecasting model, as outlined by Petropoulos (2014). Similar to his research, we will test if averaging a combination of forecasting methods offers any improvement, as well as testing model selection critea established by Hyndman (2006).
Let's get started!
M5 Dataset
As in the ADIDA tutorial, we'll use the M5 dataset, which contains the sales data of 30,490 products at Walmart over 1913 days.
Import Pandas and Numpy and then read in the sales_train_validation.csv file.
import numpy as np
import pandas as pd
sales = pd.read_csv('data/sales_train_validation.csv')
sales = sales.filter(like='d_').values
As a quick inspection, we can look at the first series in the dataset and aggregate it in to weekly, monthly and quarterly buckets.
import matplotlib.pyplot as plt
ts = np.trim_zeros(sales[0,:], 'f')
buckets = {'Daily': 1, 'Weekly': 7, 'Monthly': 28, 'Quarterly': 91}
fig, ax = plt.subplots(len(buckets), figsize=(8,8))
for i, (k, v) in enumerate(buckets.items()):
trim = len(ts) % v
ts_agg = ts[trim:].reshape(-1,v).sum(axis=1)
ax[i].plot(ts_agg)
ax[i].set_title(k, x=.1, y=.8)
ax[i].set_ylim(ymin=0)
fig.supxlabel('Bucket')
fig.supylabel('Sales')
fig.suptitle('Time Series Aggregation')
plt.tight_layout()
plt.show()

As the aggregation size increases, the intermittency is reduced and is eventually removed, but at the loss of frequencies within the data.
Classifying Intermittency
Hyndman (2006) laid out a model selection process that uses the square of the coefficient of variation of the non-zero demand, $CV^2$, and mean inter-demand period, $p$, for a given time series. Each series is classified using these two values, and then either Croston's method or the Syntetos-Boylan Approximation is selected to create the forecast.
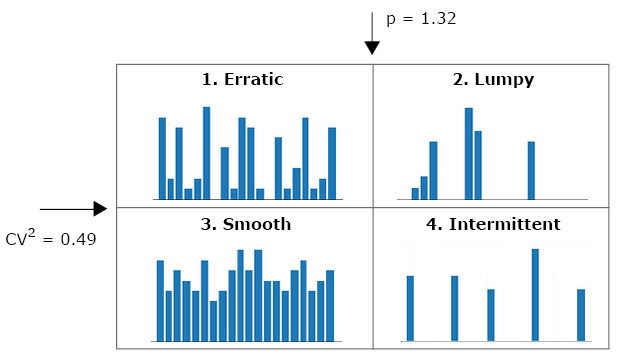
The appropriate forecasting method is given for each quadrant:
- Erratic $\rightarrow$ SBA
- Lumpy $\rightarrow$ SBA
- Smooth $\rightarrow$ Croston
- Intermittent $\rightarrow$ SBA
Let's iterate through each series in the M5 dataset and count the occurence of each type. We'll repeat this for the different sized aggregations in the buckets dictionary.
def agg(arr, s):
"""
Aggregate input 2-D array, arr, using bucket size, s.
Return a 2-D array of the aggregated series.
"""
if s == 1:
return arr
m, n = arr.shape
trim = n % s
return arr[:,trim:].reshape((m,-1,s)).sum(axis=2)
def get_quadrant(ts):
"""
Identify which quadrant a time series belongs to
"""
ts_nz = ts[ts != 0]
p_mean = len(ts) / len(ts_nz)
cv2 = (np.std(ts_nz) / np.mean(ts_nz))**2
if cv2 <= 0.49:
if p_mean <= 1.32:
return 'smooth'
return 'intmt'
else:
if p_mean < 1.32:
return 'erratic'
return 'lumpy'
# Classify intermittency and plot counts
fig, axs = plt.subplots(1,4, figsize=(12,3))
for j, (k, b) in enumerate(buckets.items()):
quadrant_count = []
sales_agg = agg(sales, b)
for i in range(len(sales_agg)):
ts = np.trim_zeros(sales_agg[i,:], 'f')
quadrant_count.append(get_quadrant(ts))
vals, counts = np.unique(quadrant_count, return_counts=True)
axs[j].bar(vals, counts)
axs[j].set_title(k)
fig.supylabel('Count')
plt.tight_layout()
plt.show()

The majority of the series are classified as intermittent - a $CV^2$ < 0.49 and $p_{mean}$ > 1.32. We would select SBA as the forecasting method for these series. As the aggregation level increases, the mean inter-demand period decreases and the series become smooth. Croston's method would then take over.
Forecasting Methods
The five forecasting methods we will be testing are Naive, Moving Average (5 point), Croston's method, Syntetos-Boylan Approximation and Simple Exponential Smoothing. These have all been assembled into the function below, pt_forecast(), which will return a single point forecast for a time series, ts.
def pt_forecast(ts, method='naive', alpha=0.1):
"""
Return a single point forecast of a 1-D time series
using the selected method. Time series has non-zero elements
trimmed from the front.
Parameters
----------
ts : (N,) array_like
1-D input array
method : {'naive', 'ma', 'cro', 'sba', 'ses'}
Forecasting method; Naive, Moving Average (5pt), Croston,
Syntetos-Boylan Approximation, Simple Exponential Smoothing
alpha : float
Smoothing factor for Croston and SBA,
`0 < alpha < 1`, default = 0.1
Returns
-------
forecast : float
Single point forecast
"""
valid_methods = {'naive', 'ma', 'cro', 'sba', 'ses'}
ts = np.trim_zeros(ts, 'f')
if method not in valid_methods:
raise ValueError(f'Valid forecasting methods: {valid_methods}')
if method == 'naive':
return ts[-1]
elif method == 'ma':
return np.mean(ts[-5:]) # 5-point moving average
elif method == 'ses':
n = len(ts) + 1
forecast = np.zeros(n)
forecast[0] = ts[0]
for i in range(1,n):
forecast[i] = alpha*ts[i-1] + (1-alpha)*forecast[i-1]
return forecast[-1]
else:
z = ts[ts != 0]
p_idx = np.flatnonzero(ts)
p = np.diff(p_idx, prepend=-1)
n = len(z)
z_hat = np.zeros(n)
p_hat = np.zeros(n)
z_hat[0] = z[0]
p_hat[0] = np.mean(p)
for i in range(1,n):
z_hat[i] = alpha*z[i] + (1-alpha)*z_hat[i-1]
p_hat[i] = alpha*p[i] + (1-alpha)*p_hat[i-1]
forecast = (z_hat / p_hat)[-1]
if method == 'sba':
forecast *= (1 - alpha/2)
return forecast
We will also test the automated model selection based on the $CV^2$ and $p_{mean}$, which has been constructed in the function below. For series where intermittence has been completely removed (ie, the mean inter-demand period is equal to 1), it will switch to Simple Exponential Smoothing.
def auto_sel(ts):
"""
Select the appropriate forecasting method using the
CV^2 and period (mean) values.
"""
ts = np.trim_zeros(ts,'f')
ts_nz = ts[ts != 0]
p_mean = len(ts) / len(ts_nz)
cv2 = (np.std(ts_nz) / np.mean(ts_nz))**2
if p_mean == 1:
return 'ses'
cv2 = (np.std(ts) / np.mean(ts))**2
if cv2 <= 0.49 and p_mean <= 1.32:
return 'cro'
else:
return 'sba'
Error metrics
For each forecasting method, we will test its performance with the five error metrics used by Petropoulos (2014). The error will be calculated for each series using the final 28 days as a test set. The error will then be scaled and averaged across the entire dataset. The metrics are
- Scaled Mean Error (sME)
- Scaled Mean Absolute Error (sMAE)
- Scaled Mean Squared Error (sMSE)
- Scaled Mean Periods in Stock (sMPIS)
- Scaled Mean Absolute Periods in Stock (sMAPIS)
The below function will return a dictionary of the error metrics when a training set, test set and forecast array are passed.
def error(train, test, forecast):
"""
Return a dictionary of error metrics
Parameters
----------
train : (M, N) ndarray
M number of series of length N.
test : (M, H) ndarray
Test set, forecasting horizon H
forecast : (M,1) or (M, H) ndarray
Either a single point forecast or an
array the same shape as the test set
Returns
-------
err : dict
Dictionary of scaled error metrics
"""
train_mean = []
for i in range(len(train)):
ts_mean = np.trim_zeros(train[i,:], 'f').mean()
train_mean.append(ts_mean)
e = test - forecast
cfe = np.cumsum(test - forecast, axis=1)
pis = -np.cumsum(cfe, axis=1)
err = {
'sME': np.mean(e, axis=1),
'sMAE': np.mean(np.abs(e), axis=1),
'sMSE': np.mean(e**2, axis=1) / train_mean, # Later it will end up scaled by 1/train_mean**2
'sMPIS': pis[:,-1],
'sMAPIS': np.abs(pis[:,-1])
}
for k, v in err.items():
err[k] = np.mean(v / train_mean)
return err
Combining Multiple Aggregation Levels and Forecasting Methods
We will test a range of approaches to see how each performs, these will include:
- Original time scale for each forecasting method (baseline)
- Using a single aggregation level (ADIDA)
- Averaging forecasts from multiple aggregation levels
- Averaging forecasts from multiple methods at a single aggregation level
- Averaging forecasts from multiple methods at multiple aggregation levels
Since we will be combining the forecasts in different ways, we only want to calculate the forecast once. Otherwise it's going to be an unnecessarily slow process. First, we'll need a function that can aggregate an array and produce a single point forecast for each series in that array.
def forecast(train, size=1, method='naive'):
"""
Aggregate a 2-D training set and produce a single
point forecast for each row in the aggregated set
"""
m, n = train.shape
if size == 1:
pass
else:
train = agg(train, size)
forecasts = []
for i in range(m):
ts = train[i,:]
if method == 'auto':
meth = auto_sel(ts)
else:
meth = method
f = pt_forecast(ts, method=meth)
forecasts.append(f/size)
return np.array(forecasts).reshape(-1,1)
Next, we'll iterate through all of the different forecasting methods and all of the different bucket sizes, collecting the forecast array for each and storing it in a dictionary.
# Create a train/test split and set options to iterate through
train = sales[:,:-28]
test = sales[:,-28:]
methods = ['naive','ma','ses','cro','sba','auto']
buckets = [1,7,14,21,28]
# Create a dictionary of forecasts for all methods for all
# bucket sizes
f_dict = {m: {b: [] for b in buckets} for m in methods}
for m in methods:
for b in buckets:
f = forecast(train, size=b, method=m)
f_dict[m][b] = f
We can now retreive the forecast array at a given aggregation level and forecast method. Eg, if we want the forecast for a aggregation level of 7 days using Croston's method, we can call f_dict['cro'][7].
Different approaches can now be tested by taking the mean of multiple forecasts. We'll use two functions for this combination, the first is comb_buckets() which will take the mean of multiple bucket sizes. The second function, comb_methods(), will take the mean of multiple forecasting methods.
def comb_buckets(f_dict, method, buckets):
"""
Return mean forecast for selected bucket sizes and method
"""
forecast = [f_dict[method][b] for b in buckets]
return np.mean(forecast, axis=0)
def comb_methods(f_dict, methods, buckets):
"""
Return mean of all forecasting methods for all
buckets
"""
forecasts = []
for m in methods:
f = comb_buckets(f_dict, m, buckets)
forecasts.append(f)
return np.mean(forecasts, axis=0)
Finally, we can iterate through all the different approaches and compile the results in a Pandas dataframe.
# Format of approaches dict is:
# 'Name of approach': [
# List of forecasting methods to be tested,
# List of aggregation sizes,
# Boolean - whether to combine forecast methods,
# ]
approaches = {
'Original Series': [methods, [1], False],
'Monthly Aggregation':[methods, [28], False],
'Multiple Aggregation':[methods, buckets, False],
'Combo - Original Series':[methods[:-1], [1], True],
'Combo - Monthly Aggregation':[methods[:-1], [28], True],
'Combo - Multiple Aggregation':[methods[:-1], buckets, True],
}
# Construct a dataframe of results, get error metrics
results = pd.DataFrame([], columns=['Method', 'Agg Levels'])
for k, v in approaches.items():
m, b, combine = v
if combine:
f = comb_methods(f_dict, methods=m, buckets=b)
err = error(train, test, f)
err = pd.DataFrame(err, index=[k])
err['Agg Levels'] = ', '.join(str(bucket) for bucket in b)
err['Method'] = ', '.join(str(method) for method in m)
results = pd.concat([results,err], axis=0)
else:
for m_ in m:
f = comb_buckets(f_dict, method=m_, buckets=b)
err = error(train, test, f)
err = pd.DataFrame(err, index=[k])
err['Agg Levels'] = ', '.join(str(bucket) for bucket in b)
err['Method'] = m_
results = pd.concat([results,err], axis=0)
# Format and display results dataframe
results = (results
.reset_index()
.rename({'index': 'Approach'}, axis=1)
.round({'sME': 3, 'sMAE': 3, 'sMSE':2, 'sMPIS':2, 'sMAPIS':2})
)
results
Results
Starting with the original series, we see that there is better performance from SES, Croston's method and SBA when considering the sMSE and sMAPIS. However, the Naive forecast has the smallest bias (sME). When we classified the type of intermittence earlier, we saw the majority of series were considered 'intermittent'. The 'auto' model would be selecting SBA in these instances, which is why the metrics between SBA and auto are almost identical.
Monthly Aggregation
Aggregating at a single bucket size is the ADIDA approach, and we see improvements in the Naive and MA forecasts. As the intermittence is mostly removed, Croston's method and SBA lose their edge. A Naive forecast performs the best across all most metrics.
Multiple Aggregation
Combining forecasts from multiple aggregation levels has the lowest sMSE for Croston, SBA and, subsequently, the Auto-selection model. The bias remains the lowest in the Naive model, but this also has the highest sMAPIS error. The sMAE is relatively flat across all models. Combining multiple aggregation levels doesn't appear to give much of an advantage over the monthly aggregation. If using Croston's method or SBA, the original series with no aggregation still performs better.
Combining Forecast Methods
When combining multiple forecasting methods at a single aggregation level, we see a fairly average result. Most metrics are around the middle of the pack when compared to their single forecast counterparts. However, when combining both forecast methods at all aggregation levels (ie throwing the kitchen sink at it), we get a more robust performance across the board.
fig, axs = plt.subplots(5, figsize=(5,10))
for i in range(5):
axs[i].boxplot(results.iloc[2:,3+i],
labels=[results.columns[3+i]],
vert=False)
axs[i].scatter(results.iloc[20,3+i],1,
marker='x', s=100,
label='Combo - Multiple Aggregation')
axs[0].legend(loc=(1.05,0.7))
plt.subplots_adjust(hspace=.4)
plt.show()

Conclusion
Combining multiple forecasting methods across multiple aggregation levels proved to be a robust approach for the M5 dataset. While it did not produce the lowest error for any one metric, its performance was generally better than average across the board. This is helpful for real-world situations where stock can be ordered at a more optimal level without having to select a forecasting model or choose parameters (ie aggregation level for ADIDA).
As noted by Petropoulos (2014), the question remains as to how high an aggregation level we should choose. In this tutorial we selected 28 days as the maximum, but we could continue to aggregate further to quaterly, bi-annually, annually etc. In the ADIDA tutorial, we noted that some series performed best at an annual aggregation level.
The auto selection approach, based in the $CV^2$ and $p_{mean}$, did not outperform its constituent models as hoped and only offered a middle ground. Perhaps the classification of time series could be improved using a different selection scheme.
References
Hyndman, R. 2006. A Note on the Categorization of Demand Patterns. Journal of the Operational Research Society 57, 1256-1257.
Petropoulos, F., 2014. Forecast Combinations for Intermittent Demand. Journal of the Operational Research Society 66, 914–924.