Croston's Method
Croston's method was developed to create forecasts for time series with intermittent demand. The method involves breaking down a series into two separate components. The first is the non-zero demand, which is the time series when all zero elements have been removed. The second series is the interval between these non-zero demand occurrences. Simple Exponential Smoothing is then performed on both of these two new series.
We will run through two approaches for calculating Croston's method, then assemble the procedure into a Python function for later use.
A Quick Example
Let's say we have the time series below, which are the sales figures for Steven Seagal's new line of cook books. Unfortunately, sales are not going well and there are days where no sales were recorded.
| Day | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sales ($y$) | 2 | 0 | 0 | 1 | 0 | 5 | 4 | 0 | 0 | 3 | 0 | 0 | 1 | 1 |
To perform Croston's Method, we need to create two new series - one for the demand and a second for the time-interval between the demand. The first series is easy - just remove all the zeros. We'll call this the demand, $z$, which will have a new index, time, t. The second series is going to be the interval between the demand, in this case the number of days between each book sale, which we will call the period, $p_t$. The first element in the period series will be 1 as there was a sale recorded on the first day. If the first sale was on day 2, then the period series would begin with 2.
| Time (t) | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| Demand ($z_t$) | 2 | 1 | 5 | 4 | 3 | 1 | 1 |
| Period ($p_t$) | 1 | 3 | 2 | 1 | 3 | 3 | 1 |
We have one series for the demand and one for the demand period. If we decided to take the mean of both series, we would have a mean demand of 2.125 and a mean period of 2.0. This is essentially saying: we sell an average of 2.125 books every 2.0 days. Instead of taking the mean of the series, Croston's method uses exponential smoothing. This is effectively just a weighted average - the strongest weight is given to the most recent figure and the weights exponentially decay as it moves back in time through the series.
Exponential Smoothing
Simple Exponential Smoothing is performed on both the demand, $z_t$, and period, $p_t$. The equations are,
$$\hat{z}_{t} = \alpha z_{t-1} + (1 - \alpha)\hat{z}_{t-1}$$$$\hat{p}_{t} = \alpha p_{t-1} + (1 - \alpha)\hat{p}_{t-1}$$where $\alpha$ is the smoothing factor, which must have a value between 0 and 1. A higher value for the smoothing factor will be more sensitive to recent values in the series. A low smoothing factor will act more like the mean of the series.
We will begin by setting, $\hat{z}_2 = z_1$ and $\hat{p}_2$ to be mean of all periods.
| Time (t) | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| Demand ($z_t$) | 2 | 1 | 5 | 4 | 3 | 1 | 1 |
| Smoothed Demand ($\hat{z}_t$) | 2 | ||||||
| Period ($p_t$) | 1 | 3 | 2 | 1 | 3 | 3 | 1 |
| Smoothed Period ($\hat{p}_t$) | 2 |
To begin smoothing, we'll need a value for alpha, so we'll set $\alpha=0.1$. We can then calculate the values for t=3.
$$\begin{aligned} \hat{z}_{3} &= (0.1 * 1.0) + (1 - 0.1) * 2 \\ &= 1.9 \end{aligned}$$$$\begin{aligned} \hat{p}_{3} &= (0.1 * 3.0) + (1 - 0.1) * 2.0 \\ &= 2.1 \end{aligned}$$This procedure can then be repeated for the remainder of the time series and we will end up with the following values.
| Time (t) | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| Demand ($z_t$) | 2 | 1 | 5 | 4 | 3 | 1 | 1 | |
| Smoothed Demand ($\hat{z}_t$) | 2 | 1.9 | 2.21 | 2.39 | 2.45 | 2.31 | 2.17 | |
| Period ($p_t$) | 1 | 3 | 2 | 1 | 3 | 3 | 1 | |
| Smoothed Period ($\hat{p}_t$) | 2 | 2.1 | 2.09 | 1.98 | 2.08 | 2.17 | 2.05 |
Making a Forecast
We can create a series for the forecast, $\hat{y}$, by dividing the smoothed demand by the smoothed period.
$$\hat{y}_t = \frac{\hat{z}_{t}} {\hat{p}_{t}}$$| Time (t) | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| Smoothed Demand ($\hat{z}_t$) | 2 | 1.9 | 2.21 | 2.39 | 2.45 | 2.31 | 2.17 | |
| Smoothed Period ($\hat{p}_t$) | 2 | 2.1 | 2.09 | 1.98 | 2.08 | 2.17 | 2.05 | |
| Forecast ($\hat{y}_t$) | 1.00 | 0.90 | 1.06 | 1.21 | 1.18 | 1.06 | 1.06 |
The forecast series can be reindexed back to the original time series, days where no sales occurred are filled with the previous forecast value.
| Day | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Actual Sales ($y$) | 2 | 0 | 0 | 1 | 0 | 5 | 4 | 0 | 0 | 3 | 0 | 0 | 1 | 1 | |
| Forecast ($\hat{y}_t$) | 1.00 | 1.00 | 1.00 | 0.90 | 0.90 | 1.06 | 1.21 | 1.21 | 1.21 | 1.18 | 1.18 | 1.18 | 1.06 | 1.06 |
The final value of 1.60 will then be used as the forecast, until the next demand updates it.
A Python Implementation
Let's repeat this procedure using Python. Import Numpy and create the example array from above.
import numpy as np
ts = np.array([2,0,0,1,0,5,4,0,0,3,0,0,1,1])
print(ts)
Step 1 - Create a non-zero series for demand
We will take the time series, ts, and extract only the non-zero elements.
z = ts[ts != 0]
print('Demand, z: ', z)
Step 2 - Create a series for the demand period
We need the time interval between each sale. We can get the index numbers of the non-zero elements using Numpy's flatnonzero() function. We then use numpy.diff() to calculate the difference between these values.
p_idx = np.flatnonzero(ts)
print('Index: ', p_idx)
p = np.diff(p_idx, prepend=-1)
print('Period, p: ', p)
Step 3 - Perform SES on both series
We set alpha, initialise the arrays and follow the Simple Exponential Smoothing procedure.
alpha = 0.1
n = len(z)
z_hat = np.zeros(n)
p_hat = np.zeros(n)
z_hat[0] = z[0]
p_hat[0] = np.mean(p)
for i in range(1,n):
z_hat[i] = alpha*z[i] + (1-alpha)*z_hat[i-1]
p_hat[i] = alpha*p[i] + (1-alpha)*p_hat[i-1]
print('Smoothed Demand, z_hat: ', np.round(z_hat,2))
print('Smoothed Period, p_hat: ',np.round(p_hat,2))
Step 4 - Calculate the forecast
The forecast array can then be calculated by dividing the z_hat and p_hat arrays.
y_hat = z_hat / p_hat
print('Forecast: ', np.round(y_hat, 2))
Great, the forecast matches what was previously calculated. We can now revert back to the original time index.
m = len(ts) + 1
forecast = np.empty(m)
forecast[:] = np.nan
forecast[p_idx+1] = y_hat
# Forward fill missing values with previous forecast
for i in range(1,m):
if np.isnan(forecast[i]):
forecast[i] = forecast[i-1]
And a quick plot of what it looks like.
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(9,5))
plt.bar(np.arange(1,m), ts, color='lightgrey', label='Actual')
plt.plot(np.arange(1,m+1), forecast, linestyle='--', label='Forecast')
plt.xticks(np.arange(1,m+1))
plt.xlabel('Time')
plt.legend()
plt.show()

Alternate Approach with Update Rules
Another approach is to stay in the index of the original time series and update $z_t$ and $p_t$ when demand occurs. Note that a demand period counter, $q$, has been introduced.
$$ \text{if } y_t > 0\text{, then } \begin{cases} {z}_{t+1} = \alpha y_{t} + (1 - \alpha){z}_{t} \\ {p}_{t+1} = \alpha q + (1 - \alpha){p}_{t} \\ q = 1 \end{cases} $$If no demand occurs at $y_t$, then $z_t$ and $p_t$ are taken as their previous values. The period counter, $q$, increments by one.
$$ \text{if } y_t = 0\text{, then } \begin{cases} {z}_{t+1} = z_{t} \\ {p}_{t+1} = p_{t} \\ q = q + 1 \end{cases} $$def croston(ts, alpha=0.1):
"""
Perform Croston's method on a time series, ts, and return
a forecast
Parameters
----------
ts : (N,) array_like
1-D input array
alpha : float
Smoothing factor, `0 < alpha < 1`, default = 0.1
Returns
-------
forecast : (N+1,) ndarray
1-D array of forecasted values, forecast begins 1-step
after first non-zero demand in ts. Prefilled with np.nan.
"""
# Initialise arrays for demand, z, and period, p. Starting
# demand is first non-zero demand value, starting period is
# mean of all intervals
ts_trim = np.trim_zeros(ts, 'f')
n = len(ts_trim)
z = np.zeros(n)
p = np.zeros(n)
p_idx = np.flatnonzero(ts)
p_diff = np.diff(p_idx, prepend=-1)
p[0] = np.mean(p_diff)
z[0] = ts[p_idx[0]]
# Perform Croston's method
q = 1
for i in range(1,n):
if ts_trim[i] > 0:
z[i] = alpha*ts_trim[i] + (1-alpha)*z[i-1]
p[i] = alpha*q + (1-alpha)*p[i-1]
q = 1
else:
z[i] = z[i-1]
p[i] = p[i-1]
q += 1
f = z / p
nan_arr = [np.nan] * (len(ts)-n+1)
return np.concatenate((nan_arr, f))
Choosing a Value for Alpha
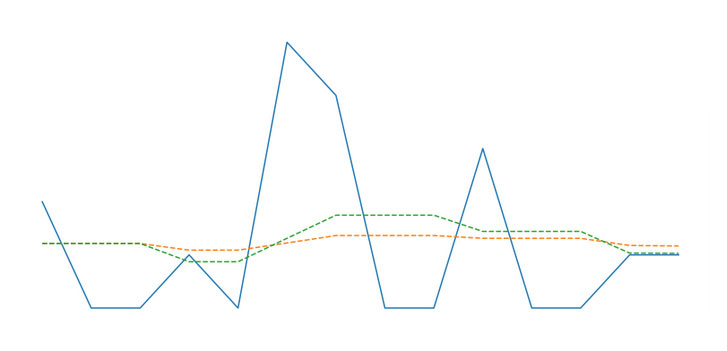
Let's create two forecasts, one with $\alpha=0.05$ and another with $\alpha=0.9$.
f_alpha_low = croston(ts, 0.05)
f_alpha_high = croston(ts, 0.9)
We can plot both forecasts to see the difference.
fig, ax = plt.subplots(figsize=(9,5))
x = np.arange(1,len(ts)+1)
f = np.arange(1,len(ts)+2)
plt.bar(x, ts, color='lightgrey', label='Actual')
plt.plot(f, f_alpha_low, linestyle='--', label='Forecast, alpha=0.05')
plt.plot(f, f_alpha_high, linestyle='--', label='Forecast, alpha=0.9')
plt.xlabel('Time')
plt.xticks(f)
plt.legend()
plt.show()

A high value for alpha results in a forecast which is more influenced by recent demand values and can therefore swing wildly. On the other hand, low values become flat and resembles the mean. So, how do we pick a value for alpha? Which forecast is better? This is discussed more deeply in the Error Metrics for Intermittent Demand tutorial, where we go over different ways to measure accuracy.
There are also adaptations of Croston's method, which aim to improve on it's vanilla flavour. Head on over to the SBA and TSB tutorial for more.